Download Cloudera.CCA-505.PassLeader.2019-08-07.21q.tqb
| Vendor: | Cloudera |
| Exam Code: | CCA-505 |
| Exam Name: | Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade |
| Date: | Aug 07, 2019 |
| File Size: | 144 KB |
Demo Questions
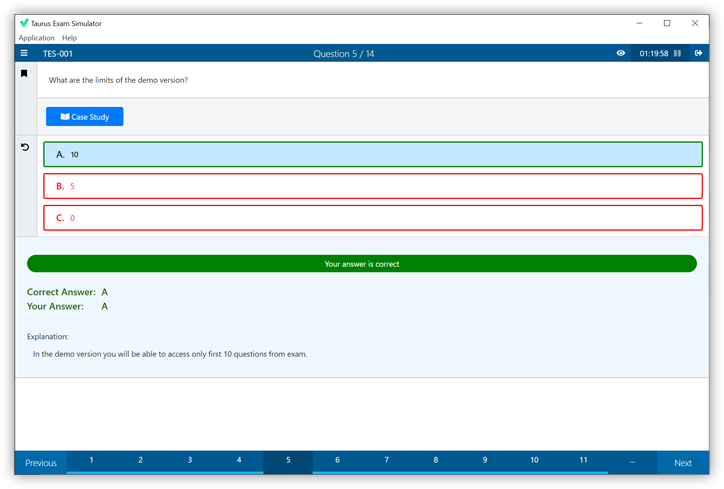
Question 1
On a cluster running CDH 5.0 or above, you use the hadoop fs –put command to write a 300MB file into a previously empty directory using an HDFS block of 64MB. Just after this command has finished writing 200MB of this file, what would another use see when they look in the directory?
- They will see the file with its original nam
- if they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster
- They will see the file with a ._COPYING_extension on its nam
- If they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster.
- They will see the file with a ._COPYING_ extension on its nam
- if they view the file, they will see contents of the file up to the last completed block (as each 64MB block is written, that block becomes available)
- The directory will appear to be empty until the entire file write is completed on the cluster
Correct answer: C
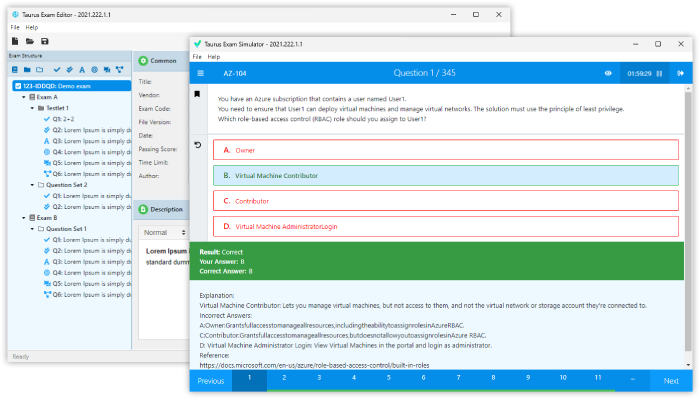
Question 2
You want to understand more about how users browse you public website. For example, you want to know which pages they visit prior to placing an order. You have a server farm of 200 web servers hosting your website. Which is the most efficient process to gather these web server logs into your Hadoop cluster for analysis?
- Sample the web server logs web servers and copy them into HDFS using curl
- Ingest the server web logs into HDFS using Flume
- Import all users clicks from your OLTP databases into Hadoop using Sqoop
- Write a MApReduce job with the web servers from mappers and the Hadoop cluster nodes reducers
- Channel these clickstream into Hadoop using Hadoop Streaming
Correct answer: AB
Question 3
Assume you have a file named foo.txt in your local directory. You issue the following three commands:
Hadoop fs –mkdir input
Hadoop fs –put foo.txt input/foo.txt
Hadoop fs –put foo.txt input
What happens when you issue that third command?
- The write succeeds, overwriting foo.txt in HDFS with no warning
- The write silently fails
- The file is uploaded and stored as a plain named input
- You get an error message telling you that input is not a directory
- You get a error message telling you that foo.txt already exist
- The file is not written to HDFS
- You get an error message telling you that foo.txt already exists, and asking you if you would like to overwrite
- You get a warning that foo.txt is being overwritten
Correct answer: E